6.2 敵対的サンプル (Adversarial Examples)
敵対的サンプルとは、機械学習モデルに間違った予測をさせる、意図的に小さな摂動を持たせたサンプルのことをいいます。 これは概念的にとても似ているため、反事実的説明についてを先に読むことをおすすめします。 敵対的サンプルは、モデルを解釈するためのものではなく、モデルを騙すことを目的とした反事実的説明だといえます。
なぜ私たちは敵対的サンプルについて学ぶ必要があるのでしょうか。これらは実用性のない、機械学習のおもしろい副産物なのでしょうか。答えは「NO」です。以下のような場合、機械学習のモデルは敵対的サンプルにより脆弱性を持つことになってしまいます。
自動運転の車が「止まれ」の標識を無視したために他の車にぶつかってしまいました。この前、誰かが標識の上に、人間には標識が少し汚れていると感じさせる程度の写真を置いていきました。しかし、車に搭載されていた標識を識別するシステムに対しては「駐車禁止」の標識と判断させるよう作られたものでした。
迷惑メールの検出器が、迷惑メールを分類することに失敗しました。迷惑メールはあたかも普通のメールに見えるよう書かれていましたが、受け取った人を騙すような内容が含まれていました。
機械学習の機能を搭載したスキャナが空港でスーツケースに入った武器の検出に用いられていました。このシステムに傘だと思わせることで検知を防ぐナイフが開発されてしまいました。
それでは敵対的サンプルを生成するいくつかの方法を見ていきましょう。
6.2.1 手法及び例
敵対的サンプルを生成する手法はいくつか存在します。 多くの手法では、予測が(敵対的な)求める値となり、かつ敵対的サンプルと元のサンプルの距離が最小化されるよう操作します。 手法には、ニューラルネットなど勾配を用いるモデルに対しこの勾配にアクセスする必要があるものや、また、予測関数にアクセスできればよく、モデルに依存せず用いることができるものなどが存在します。 この章では既に研究が多くされており、敵対画像を可視化することで多くの情報が得られる、ニューラルネットワークによる画像分類における手法に焦点を当てて説明します。 画像の敵対的サンプルでは画像の画素に意図的に特定の値を加えることで、実用段階のモデルを騙すことを目的とします。 これらの例からは、物体検知する深層ニューラルネットが人間には何の変哲もないように見える画像からいかに簡単に騙されてしまうかを見てとることができます。 これらの例を見たことがない人は、予測の変化があまりに理解できないものであることに驚くかもしれません。 敵対的サンプルは、機械にとっての目の錯覚のようなものなのです。
私の犬の何かがおかしい
Szegedyら(2013)55は "Intriguing Properties of Neural Networks" という論文の中で、勾配ベースの最適化手法を用いて深層ニューラルネットの敵対的サンプルを見つけようとしました。

FIGURE 6.2: Szegedyらの生成したAlexNetにおける敵対的サンプル(2013)。左側の列の画像は全て正しく分類される。真ん中の列は、右側の画像を生成するために画像に加えられた誤差を拡大したものを示しており、右側の画像はすべて「ダチョウ」として間違って分類されてしまう。 ("Intriguing properties of neural networks", Figure 5 by Szegedy et. al. CC-BY 3.0.)
これらの敵対的サンプルは次の関数を変数 r に関して最小化することで生成されます。
\[loss(\hat{f}(x+r),l)+c\cdot|r|\]
この式では、x は画像を表す画素値のベクトル、r は敵対画像を生成するための画素値の差分(x+r が新しい画像となる)、l は求める結果のクラス、c は画像間及び予測結果間の距離のバランスをとるためのパラメータを表します。 1項目は敵対的サンプルの予測結果と望ましいクラス l との距離であり、2項目は元の画像と敵対的サンプルの画像の距離を示しています。 この定式化は 反事実的説明 を生成するため用いられた損失関数とほぼ同じです。 ただし、こちらでは画素値が0から1の値であるための制約が加えられます。 著者らは、矩形拘束条件を持つ L-BFGS 法という、勾配ベースの最適化アルゴリズムを用いてこの最適化問題を解くことを提案しています。
Disturbed panda: Fast gradient sign method。
Goodfellowら(201456は gradient sign method と呼ばれる敵対的画像を生成するアルゴリズムを開発しました。 この手法は元となるモデルの勾配を用いることで敵対的サンプルを作成します。 元の画像 x は各ピクセルに微小な誤差 \(\epsilon\) を加えることで操作され、この誤差 \(\epsilon\) の符号は対応するピクセルの勾配の符号により決定されます。 勾配方向に対して誤差を加えることで、モデルが画像を誤認識するよう画像を意図的に変更を加えているのです。
fast gradient sign method の主な考え方は以下の式のように表されます。
\[x^\prime=x+\epsilon\cdot{}sign(\bigtriangledown_x{}J(\theta,x,y))\]
ここで、\(\bigtriangledown_x{}\) は元の入力ベクトル x に対するモデルの損失関数の勾配、y は x のラベルを表すベクトル、\(\theta\) はモデルのパラメータのベクトルを表します。 勾配ベクトルは入力画像のベクトルと同じ長さであり、ここではこの符号のみを扱います。 勾配の符号が正ならば、ピクセル値を増加させることでモデルの損失も増加し、負ならばピクセル値を下げることでモデルの損失は増加します。 この脆弱性はニューラルネットワークが入力のピクセル値とクラススコアの関係性を線形に扱う際に起こります。特に、LSTM や maxout network、ReLU を活性化関数とするネットワーク、ロジスティック回帰など、線形性を含む構造はこの手法に対して脆弱性を持ちます。 この攻撃は外挿法により実行されます。 入力画像のピクセル値とクラススコア間の線形性は外れ値に対して脆弱であり、ピクセル値をデータの分布の領域外の値とすることでモデルは騙される場合があります。 これらの敵対的サンプルはニューラルネットワークの構造に対し極めて特異的だと考えられてきましたが、この手法により同じタスクに対し訓練されたネットワークならば敵対的サンプルを使い回すことができることが明らかになりました。
Goodfellowら(2014)は敵対的サンプルを学習データに加えることでモデルをより頑健なものとすることを提案しました。
くらげ?バスタブ?: 1-pixel attack。
2014年にGoodfellowとその同僚らにより提案された手法では多くのピクセルの値を僅かに変更する必要がありました。しかし1つのピクセル値しか変えられないとしたらどうでしょうか。モデルを欺くことができるでしょうか。 Suら(2019)57 は、1つの画素値を変更するだけで画像分類モデルを欺くことが可能であることを示しました。
FIGURE 6.3: 故意に1つのピクセル値を変更することで ImageNet データセットに対して訓練されたニューラルネットは元のクラスではなく誤ったクラスを予測するようになってしまう。
反事実的説明と同様に、1-pixel attack は元画像 x に近いサンプル x’ を探し変更を加えますが、予測を敵対的な結果へと導きます。ただし、距離の近さの定義は異なり、1ピクセルのみ変えることが許可されます。1-pixel attack は差分進化を用いることで、どのピクセルをどのように変更すべきかを探索します。差分進化は生物学における種の進化を元に作られた手法で、候補解と呼ばれる個体群を反復的に組み替えて行くことで解を探索します。それぞれの候補解はピクセル値の変更を表現したものであり、xy座標及び赤、青、緑のrgb値の5つの要素により表されます。探索は、例として400の候補解(ピクセル値の変更案)から始まり、次の式を用いて新しい世代の候補解が作成されます。
\[x_{i}(g+1)=x_{r1}(g)+F\cdot(x_{r2}(g)-x_{r3}(g))\]
ここで、それぞれの \(x_i\) は候補解の要素(x座標、y座標、赤、緑、青)、g は現在の世代、F はスケーリング用パラメータ(0.5に設定)、r1、r2、r3 は異なる乱数を表します。 それぞれの新しい子の候補解は順に位置及び色の5つの特性をもつ1つのピクセルであり、これらの特性はランダムに選ばれた3つ親ピクセルの特性を混ぜ合わせたものとなります。
1つの候補解が敵対的サンプルとして、すなわち誤ったクラスに分類された場合、もしくは反復回数がユーザが指定する最大値に達した場合、子の生成は終了します。
全部トースター: 敵対的パッチ。
私が最も好きな手法の1つに、敵対的サンプルを現実世界へと拡張させるものがあります。ブラウンらは2017年、物体の横に貼り付けることで画像分類器にトースターと認識させる、印刷可能なラベルを開発しました。

FIGURE 6.4: ImageNet 上で訓練された VGG16 分類器にバナナの画像をトースターと分類させるステッカー。Brown et. al (2017)
この手法では、敵対的サンプルは元の画像とほぼ同じものである必要があるという制約が取り除かれている点で、これまでに紹介した敵対的サンプルの例とは異なっています。その代わり、この手法では画像の一部が任意の形を取ることのできるパッチによって完全に置き換えられます。パッチは多くの状況で機能するよう、画像に対するパッチの位置を変えながら、また時には大きさを変えたり回転させながら、異なる背景画像に対し最適化されます。最終的には最適化された画像は印刷され、様々な画像分類器を誤認識させるのに用いることができるようになります。
3Dプリンタで作った亀を銃撃戦に持ち込むな。たとえコンピュータがそれを良いアイディアだと思ったとしても: 頑健な敵対的サンプル
次の方法は文字通り、トースターに別の次元を足すものです。 Athalye ら(2017)58はディープニューラルネットワークにとってどう見てもライフルとしか認識できない亀を3Dプリンタを用いて作成しました。 人にとって亀に見える物質がコンピューターにとってはライフルに見えてしまうのです。
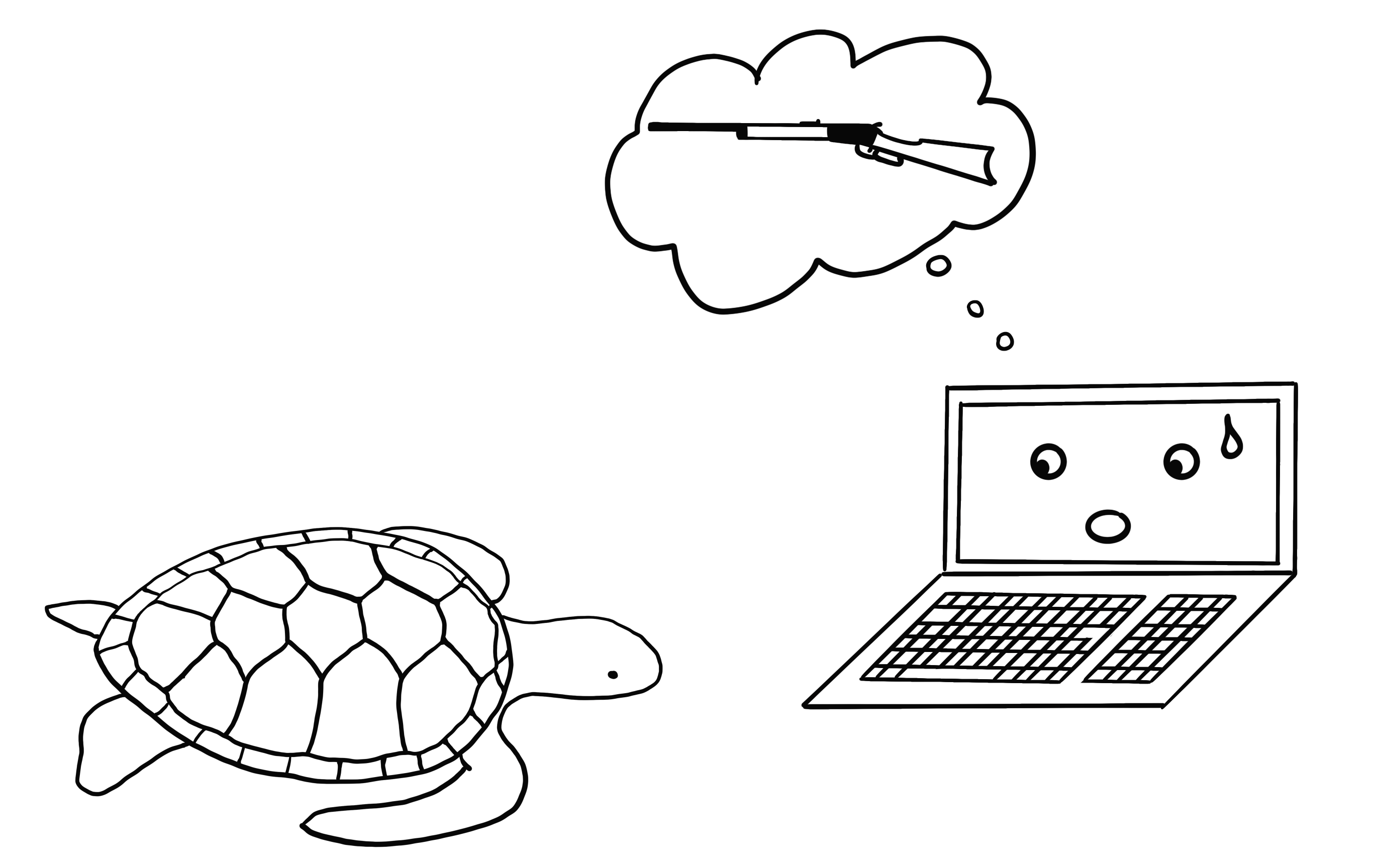
FIGURE 6.5: Athalye ら(2017)は、TensorFlow の標準的な訓練済み InceptionV3 分類器にとってはライフルにしか見えない亀を3Dプリンタで作成した。
著者らが用意した3次元的な敵対的サンプルは、画像に回転や拡大など、どんな変形を加えても、2次元画像の分類器を欺くことに成功しました。 Fast gradient法など、他の方法は画像の回転や角度の変更に対応できません。 Athalye et. al (2017)は画像の変形に頑健な Expectation Over Transformation (EOT)アルゴリズムを提案しました。 EOTはさまざまな変形に対して敵対的サンプルを最適化するというアイディアに基いています。 オリジナル画像と敵対的サンプルの距離を最小化する代わりに、EOTは様々な方法でオリジナル画像を変形した時に距離の期待値が閾値以下になるよう調整します。 変形に伴う距離の期待値は以下のように記述できます。
\[\mathbb{E}_{t\sim{}T}[d(t(x^\prime),t(x))]\]
ここで、\(x\) はオリジナル画像、\(t(x)\) は変形した画像(たとえば回転)、\(x'\) は敵対的サンプル、\(t(x')\) は変形した敵対的サンプルです。 様々な変形に加えて、EOT 法は敵対的サンプルの探索を最適化問題として扱うために、familiar pattern of framing the search を用います。 次の確率を最大化することで、変形に対して、 例えばライフルなどの選択したクラス \(y_t\) と見なす敵対的サンプル \(x'\) を見つけます。
\[\arg\max_{x^\prime}\mathbb{E}_{t\sim{}T}[log{}P(y_t|t(x^\prime))]\]
さらに、オリジナル画像 x と敵対的サンプル x' の距離の期待値が次のようにある閾値以下になるよう制約をつけます。
\[\mathbb{E}_{t\sim{}T}[d(t(x^\prime),t(x))]<\epsilon\quad\text{and}\quad{}x\in[0,1]^d\]
この方法の実現可能性について少し考えておきましょう。 他の手法はデジタル画像を操作します。 一方で、3次元に出力した頑健な敵対的サンプルは現実に登場し、コンピューターによる物体認識を阻害します。 言い方を変えてみましょう。 誰かが亀にしか見えないライフルを作ったらどうしますか。
目隠しされた敵:ブラックボックスアタック。
以下のような状況を考えてみましょう。 あなたは Web API を通して優れた画像分類器に対してアクセスできるようになりました。 ただしモデルからの予測を得ることはできますが、モデルのパラメータに対してはアクセスできません。 ソファに寝そべっていても、データを送信すればこのサービスはそのデータに対応する分類結果を送り返してくれます。 多くの敵対的手法では、敵対的サンプルの生成に元となる深層ニューラルネットワークの勾配を用いるため、このような状況には用いることができません。 Papernot と彼の同僚59は2017年、モデルに関する情報や学習データを用いることなく敵対的サンプルを生成できることを示しました。この種の、(ほぼ)前提知識を必要としない攻撃手法はブラックボックスアタックと呼ばれます。
どのように動くかを以下に示します。
- 学習データと同じ分野に属する画像を何枚か用意します。例として攻撃する分類器が数字の分類するものである場合、数字の画像を用います。その分野への知識は必要ですが、学習データへアクセスする必要はありません。
- ブラックボックスから準備した画像に対する予測結果を取得します。
- これらの画像に対するサロゲートモデル(ニューラルネットワークなど)を訓練します。
- 現在の画像セットについて、モデルの出力の分散が大きくなるようなピクセル値の操作を探索するヒューリスティックを用い、新しく合成画像のデータセットを作成します。
- 事前に定めたエポック数だけ2から4のステップを繰り返します。
- Fast Gradient Method などを用いてサロゲートモデルに対して敵対的サンプルを生成します。
- これらの敵対的サンプルを用いて元のモデルを攻撃します。
サロゲートモデルの目的はブラックボックスモデルの決定境界を推定することであり、同等の精度を求める必要はありません。
著者はクラウド上の機械学習サービス上で学習させた画像分類器に対し攻撃を仕掛けることでこの手法をテストしました。これらの画像分類器はユーザがアップロードした画像とラベルを用いて学習をします。ソフトウェアは、時にはユーザの知らないアルゴリズムを用いてモデルを自動的に学習させ、デプロイします。その後分類器はアップロードされる画像に対し予測を出力しますが、モデル自体は中身を見たりダウンロードできません。著者らは多くのプロバイダに対して敵対的サンプルを生成することに成功し、最大 84% もの敵対的サンプルが誤認識されました。
この手法は攻撃するモデルがニューラルネットワーク出ない場合でも動作します。これには決定木のような勾配を用いない学習モデルも含まれます。
6.2.2 サイバーセキュリティーの観点
機械学習は既知の分布から未知のデータ点を予測するという既知の未知を扱うものです。 攻撃に対する防御は未知の未知を扱います。敵対的な入力の未知の分布からの未知のデータを頑健に予測します。 機械学習が自動運転車や医療機器などの多くのシステムに適用されるにつれて、それらはサイバー攻撃の入り口にもなりつつあります。 テストデータセットでの機械学習モデルの予測が 100% 正しい場合でさえ、モデルを騙すための敵対的な例を見つけることができます。 サイバー攻撃から機械学習モデルを守ることは、新しいサイバーセキュリティーの一分野となっています。
Biggio ら(2018)60は、この10年の敵対的機械学習に関する研究の優れたレビューをしています。 サイバーセキュリティーは攻撃者と防御者が何度も互いを出し抜く軍拡競争です。
サイバーセキュリティーには3つの黄金則があります。1)敵を知れ 2)プロアクティブであれ 3)自分自身を守れ です。
分野が違えば、敵も異なります。 お金目当てに電子メールを使って詐欺する人々は、メールサービス利用者と電子メールサービスのプロバイダの敵です。 ユーザがメールシステムを使い続けてくれるように、プロバイダはユーザを保護したいと考える一方で、攻撃者はユーザーからお金を奪いたいと考えます。
敵を知ることは、その人たちの目標を知ることを意味します。 これらのスパマー (spammers) がいることが知らず、電子メールサービスの悪用法が音楽の海賊版の送信だけであると仮定すると、防御は異なったものになります。(例えば、スパムを判定するために文章を分析する代わりに、著作権で保護された添付ファイルをスキャンします。)
プロアクティブであるということは、システムの弱点を進んでテストして特定することを意味します。 敵対的な例を用いて、積極的にモデルを騙し、さらにそれらを防ごうと試みる時、プロアクティブだと言えるでしょう。 解釈可能なモデルを用いてどの特徴量が重要であるかや、どのように予測に影響しているかを理解しようとすることもまた、機械学習モデルの弱点を知るためのプロアクティブなステップです。
データサイエンティストとして、この危険な世界においてテストデータセットにおけるモデルの予測能力を超えて試すこと無しにモデルを信用できますか。 異なったシナリオ下でモデルがどのように振る舞うか分析し、最も重要な入力を特定し、複数の例で予測の説明性を試しましたか。 敵対的な入力を見つけようとしたことがありますか。 機械学習モデルの解釈可能性はサイバーセキュリティーにおいて大きな役割を果たします。 プロアクティブと反対に、リアクティブであるということは、システムが攻撃されるまで何も策を講じず、攻撃されて初めて問題点を認識し守るための指標を取り入れることを意味します。
どうすれば敵対的サンプルから自分の機械学習モデルのシステムを守ることができるでしょうか。 プロアクティブなアプローチとしては敵対的サンプルを用いたクラス分類の反復学習が挙げられます。これは敵対的学習とも呼ばれます。 他のアプローチとしては、ゲーム理論に基づいた方法で、特徴量の不変変換学習やロバスト最適化(正則化)なども存在します。
他には、単一ではなく複数の分類器を用いて予測を投票(アンサンブル)で決定する手法も挙げられますが、全ての分類器が同様な敵対的サンプルに苦しむ可能性があるため、正しく機能する保証はありません。 さらに別のアプローチとしては、元のモデルの代わりに最も近い分類器を使うことで有用な勾配を用いないモデルを構成する、勾配マスキングもありますが、これもまた上手く機能しません。
攻撃者のシステムに対する理解度に応じて、攻撃の種類を区別できます。 まず、攻撃者が完璧な知識、つまりモデルの種類、パラメータ、学習データの情報を持っているパターン(white box attack)があります。 次に、攻撃者が部分的な情報しか持っていないパターン(gray box attack)があります。攻撃者が使用された特徴量の代表的なものと、モデルの種類しか知らず、学習データやパラメータにはアクセスできない場合がそれにあたります。 最後に、攻撃者が何の知識も持っていないパターン(black box attack)があります。この場合、攻撃者はブラックボックスなモデルから結果を取り出すことだけが出来て、学習データやモデルパラメータについての情報にはアクセス出来ません。
モデルを攻撃するため、敵は情報の程度に応じて異なるテクニックを用います。 例で見たように、ブラックボックスの場合でさえ敵対的サンプルを生成できるため、データやモデルの情報を隠すことは攻撃から身を守るために効果的ではありません。
攻撃者と防御者の関係はいたちごっこになるため、この分野では多くの開発とイノベーションが見られます。 スパムメール1つ取っても、そこには多くの種類が生じており、絶え間なく進化しています。 機械学習モデルに対する新しい攻撃手法が発明されては、それらに対する新しい防御策が提案されています。 最新の防御手法を回避するために、より強力な攻撃が開発され、それが永遠に続きます。 この章を通して、読者が敵対的サンプルの問題に対し敏感になることを願っています。 そしてその問題は機械学習モデルをプロアクティブに研究することによってのみ、弱点を発見し修正できます。
Szegedy, Christian, et al. "Intriguing properties of neural networks." arXiv preprint arXiv:1312.6199 (2013).↩
Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. "Explaining and harnessing adversarial examples." arXiv preprint arXiv:1412.6572 (2014).↩
Su, Jiawei, Danilo Vasconcellos Vargas, and Kouichi Sakurai. "One pixel attack for fooling deep neural networks." IEEE Transactions on Evolutionary Computation (2019).↩
Athalye, Anish, and Ilya Sutskever. "Synthesizing robust adversarial examples." arXiv preprint arXiv:1707.07397 (2017).↩
Papernot, Nicolas, et al. "Practical black-box attacks against machine learning." Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security. ACM (2017).↩
Biggio, Battista, and Fabio Roli. "Wild Patterns: Ten years after the rise of adversarial machine learning." Pattern Recognition 84 (2018): 317-331.↩