1.3 専門用語
曖昧さによる混乱を避けるために、この本で使用する用語の定義をいくつか紹介します。
アルゴリズム (Algorithm) とは、特定のゴール2を達成するために機械が従うルールの集まりのことです。アルゴリズムは、入力と出力、および入力から出力を得るために必要な全てのステップを定義するレシピのようなものと見なすことができます。 料理のレシピは、食材を入力、調理された食品を出力、準備や調理手順がアルゴリズムの指示であるようなアルゴリズムと言えます。
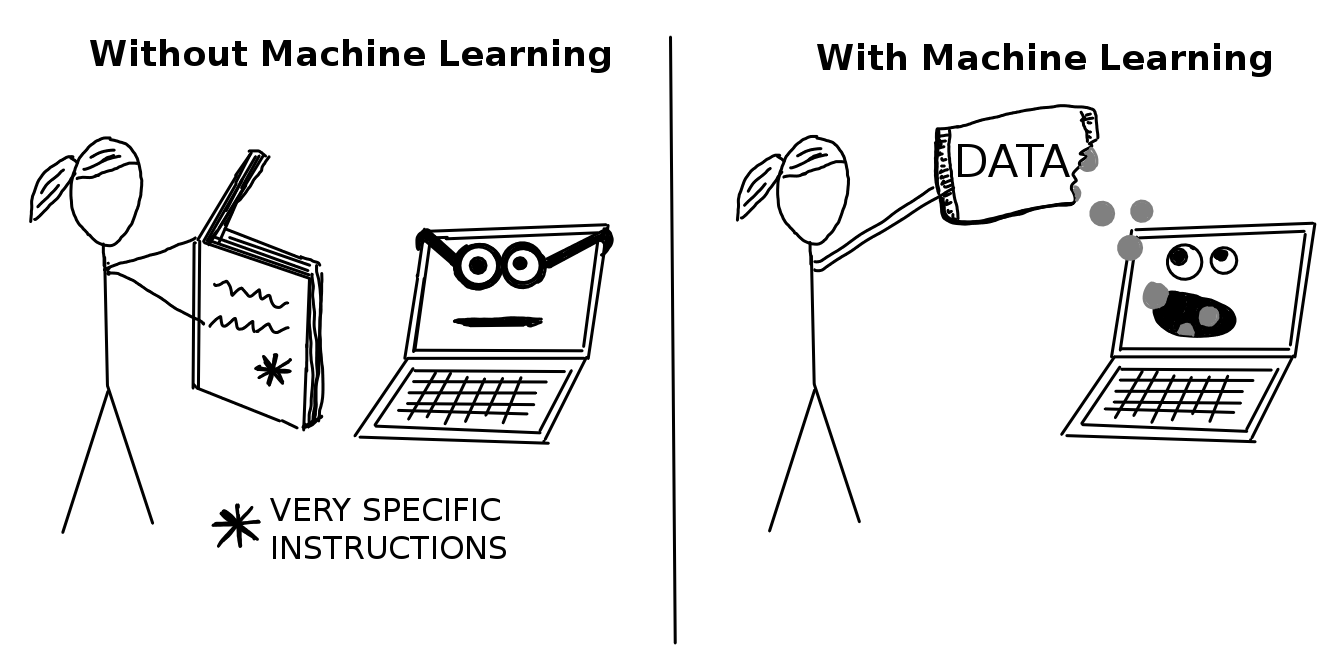
機械学習 (Machine Learning) はコンピュータがデータから学習して予測 (例えば、がん、売り上げ、債務不履行) を行い、改善することを可能にする手法の集まりのことです。 機械学習によって、全ての命令を明示的にコンピュータに与える必要がある”従来のプログラミング”から、データを提供することで行われる”間接的なプログラミング”へのパラダイムシフトが起こりました。
学習器 (Learner) または 機械学習アルゴリズム はデータから機械学習モデルを学習するためのプログラムのことを言います。別の名前は、”inducer” (例えば, “tree inducer”)とも言います。
機械学習モデル (Machine Learning Model)とは、入力に対して予測を対応づける学習されたプログラムのことを言います。これは、線形モデルやニューラルネットワークの重みの集合とも言えます。 この曖昧な単語である“モデル”の別の言い方として、”predictor” または、タスクに応じて “classifier” や “regression model” と言うこともあります。
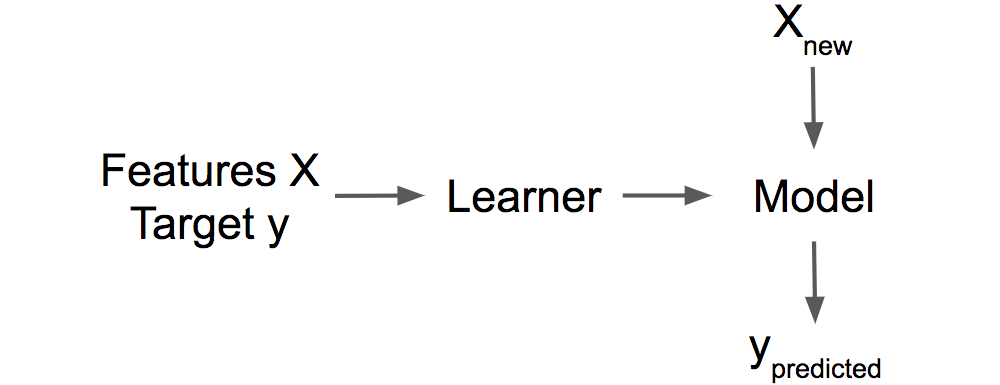
FIGURE 1.1: ラベル付きの学習データから学習器がモデルを学習する様子 モデルは予測を行うために使用される。
ブラックボックスモデル (Black Box Model)とは、内部の機構が明らかになっていないシステムのことを言います。機械学習の文脈では、”ブラックボックス”は、例えばニューラルネットワークのような、学習された重みを見ても人間が理解できないモデルのことを指しています。 ブラックボックスの反対は”ホワイトボックス”であり、この本では interpretable model として紹介されています。

解釈可能な機械学習 (Interpretable Machine Learning) は、機械学習システムの振る舞いや予測を人間にとって理解可能なものにするための手法やモデルのことを言います。
データセット (Dataset) は機械が学習するデータを含むテーブルのこととします。 データセットは特徴量 (features) と予測の目的値を持っています。 モデルを学習する際に使われたデータセットのことを学習データと呼びます。
インスタンス (Instance) はデータセットの行のことを言います。 インスタンスの別の言い方は、データ点 (data point)、例 (example)、観測 (observation)です。 インスタンスは特徴量の値\(x^{(i)}\)と、もし既知なら、目的値の\(y_i\)からなります。
特徴量 (Features) は予測やクラス分類に使われる入力のことです。 特徴量はデータセットの列に対応します。 この本を通して、特徴量そのものは解釈可能、つまり、気温や日、人間の身長など、意味が簡単に理解可能なものであるとします。 なぜなら、仮に入力特徴量の理解が困難であれば、学習されたモデルの理解もまた難しくなるからです。 全ての特徴量からなる行列をXと呼び、\(x^{(i)}\)は1つのインスタンスのこととします。 すべてのインスタンスに対する1つの特徴量を並べたベクトルを\(x_j\)として、インスタンス i に対する特徴量 j の値は \(x^{(i)}_j\) とします。
目標値 (Target) とは機械が学習する予測の情報 のことです。 数式の中では、目標値は y や 1つのインスタンスに対しては \(y_i\) と呼ばれます。
機械学習タスク (Machine Learning Task) はデータセットの特徴量と目標値の組み合わせのことです。目標値のタイプにしたがって、タスクは例えばクラス分類、回帰、生存分析、クラスタリング、異常検知となります。
予測 (Prediction) は、与えられた特徴量に対して、機械学習モデルが 目標値がどうあるべきか“推測” した結果のことを言います。 この本では、モデルの予測は \(\hat{f}(x^{(i)})\) または \(\hat{y}\) と表記します。
"Definition of Algorithm." https://www.merriam-webster.com/dictionary/algorithm. (2017).↩