7.1 学習された特徴量
This chapter is currently only available in this web version. ebook and print will follow.
畳み込みニューラルネットワークは抽象的な特徴量や、元画像ピクセルから概念を学習します。 特徴量の可視化では学習された特徴量を activation maximization により可視化します。 ネットワーク分析ではニューラルネットワークのユニット(チャネルなど)を人間の理解によってラベル付けします。
深層ニューラルネットワークは隠れ層で高レベルの特徴量を学習します。 これは深層ニューラルネットワークの最も重要な強みの1つで、特徴量に関する作業を減らします。 サポートベクターマシンによる画像分類器を構成したいと仮定して下さい。 生のピクセル行列は SVM の訓練に最も良い入力形式ではないため、色、周波数領域、輪郭検出器などの新たな特徴量を作りだす必要があります。 畳み込みニューラルネットワークでは、画像は生の形式(ピクセル)のままネットワークに与えられます。 ネットワークは画像を何度も変換します。 初めに、画像は多数の畳み込み層を通過します。 それらの畳み込み層では、ネットワークは新たな、そして次第に複雑な特徴量をその層において学習します。 その後、変換された画像の情報は全結合層を通過し、分類や予測へ変化します。

FIGURE 7.1: ImageNet データにより訓練された畳み込みニューラルネットワーク (Inception V1) による、学習された特徴量。特徴量は、低い畳み込み層(左)の単純な特徴量から、高い畳み込み層(右)のより抽象的な特徴量までの範囲を持つ。Olah, et al. 2017 (CC-BY 4.0) https://distill.pub/2017/feature-visualization/appendix/.
- 最初の畳み込み層は輪郭や単純なテクスチャといった特徴量を学習します。
- その後の畳み込み層はより複雑なテクスチャや模様といった特徴量を学習します。
- 最後の特徴量は物体や物体の一部といた特徴量を学習します。
- 全結合層は、高レベル特徴量からの活性化を予測されるべき個別のクラスへと接続するよう学習します。
クールですね。 しかし、実際にはどのようにそんな幻覚めいた画像を得ているのでしょうか?
7.1.1 特徴量の可視化
学習された特徴量を明示的なものにしようとする試みを特徴量の可視化と呼びます。 ニューラルネットワークのあるユニットの特徴量の可視化はその部分の活性化関数を最大化する入力を見つけることによって行います。
「ユニット」はそれぞれのニューロン、チャンネル(特徴量マップとも呼ばれる)、全体の層、およびクラス分類における最終的なクラスの確率(や対応するソフトマックスの前のニューロン、これが推奨される)のことを指します。
しかし、問題があります。 ニューラルネットはしばしば何百万ものニューロンを含むことがあります。 それぞれのニューロンの特徴量の可視化を見ることはあまりにも時間がかかりすぎるでしょう。 ユニットとしてのチャンネル(activation map とも呼ばれることもある) は特徴量を可視化するのに良い選択となります。 もう一段上がって全体の畳み込み層を可視化できます。 ユニットとしての層が Google の DeepDream で使われています、これは元の画像に繰り返し可視化された特徴量を加えることで、入力の夢バージョンを出力するものです。
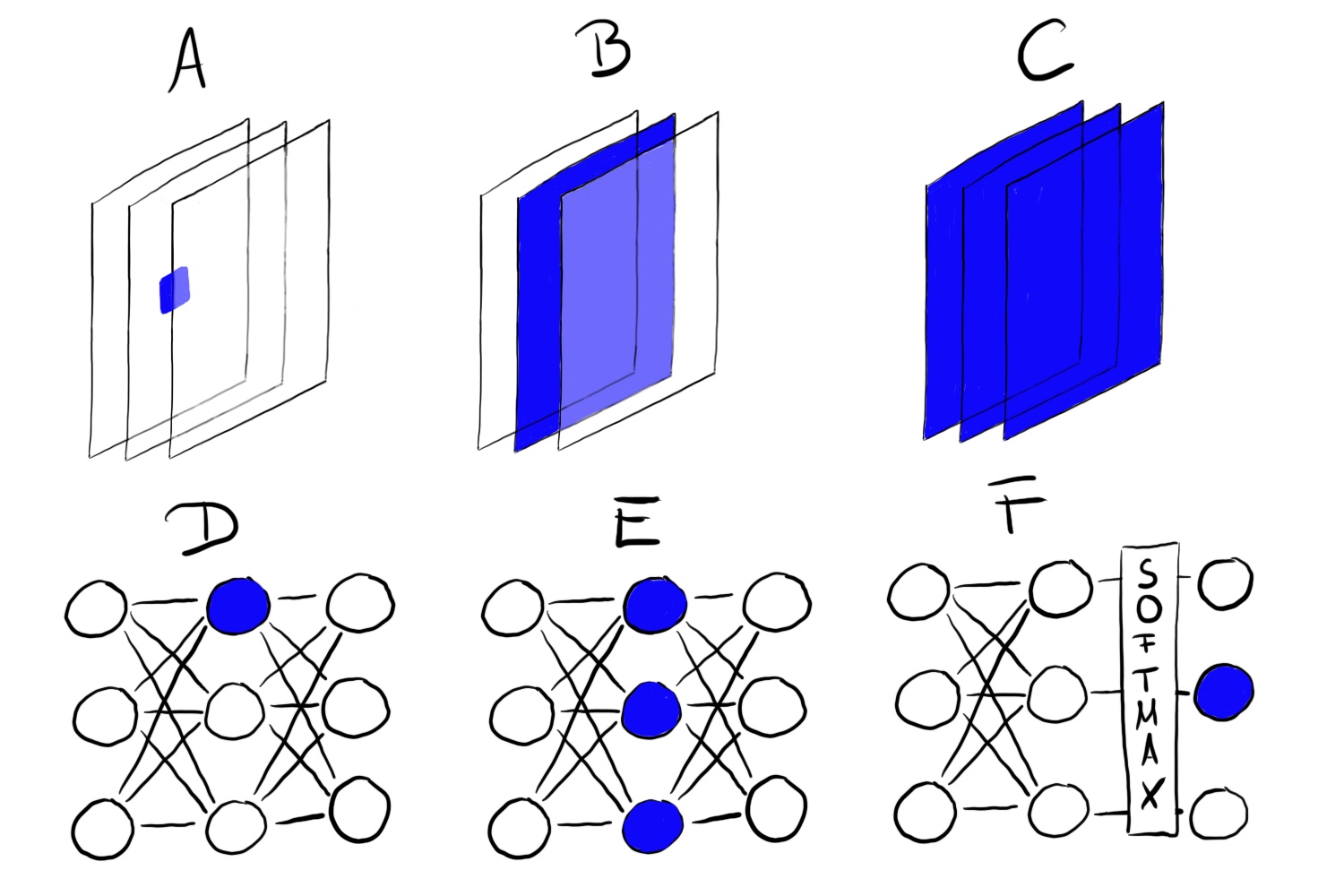
FIGURE 7.2: 特徴量の可視化は異なるユニットで行うことができる。A)畳み込みニューロン、B)畳み込みチャンネル、C)畳み込み層、D)ニューロン、E)隠れ層、F)クラス確率を示すニューロン(または、それに対応するソフトマックスの前のニューロン)
7.1.1.1 最適化を通した特徴量の可視化
数学的な観点では、特徴量の可視化は最適化問題になります。 ニューラルネットワークの重みが固定されていると仮定します。これはネットワークが学習済みであることを意味します。 ユニット、ここでは1つのニューロンを指しますが、の活性化関数の計算結果(の平均)を最大化する新しい画像を探します。
\[img^*=\arg\max_{img}h_{n,x,y,z}(img)\]
関数 \(h\) はニューロンの活性化関数、img はネットワークの入力(画像)、x と y はニューロンの空間的な位置を表していて、n は層を特定し、z はチャンネルのインデックスです。 層 n のチャンネル z の全体の活性化関数の計算結果の平均を最大化するには次式のようにします。
\[img^*=\arg\max_{img}\sum_{x,y}h_{n,x,y,z}(img)\]
この方程式では、チャンネル z のすべてのニューロンが等しく重み付けされています。 あるいは、ランダムな方向に最大化できて、これはニューロンが負の方向を含む様々なパラメータをかけられることを意味します。 このようにして、ニューロンがチャンネルにどのように作用するかを学びます。 活性化関数を最大化するかわりに、最小化もできます(これは負の方向に最大化することに相当します)。 面白いことに、負の方向に最大化すると同じユニットでも全く異なる特徴量が得られます。

FIGURE 7.3: Inception V1 の、ReLU の前の mixed4d 層のニューロン484 の正(左)と負(右)の活性化関数の値。ニューロンは車輪で最大に活性化されている一方、目を持つようなものが負の活性化を産んでいます。コード: https://colab.research.google.com/github/tensorflow/lucid/blob/master/notebooks/feature-visualization/negative_neurons.ipynb
この最適化問題に異なる方法で取り組むことができます。 はじめに、なぜ新しい画像を作るべきなのでしょうか。 単純に学習する画像を検索して、活性化関数を最大化するもの選ぶこともできます。
これは有効なアプローチですが、学習データを使うことは画像の要素が一致してしまい、ニューラルネットが本当に探しているものがわからなくなるという問題があります。 もしある特定のチャンネルをよく活性化させる画像が犬やテニスボールを示していたら、ニューラルネットワークが犬を見ているのか、テニスボールを見ているのか、はたまた両方を見ているのかわかりません。
別のアプローチはランダムなノイズから始めて新しい画像を生成することです。 意味のある可視化を得るために、例えば少しの変化しか許容しないなど、たいてい画像に対する制約があります。 特徴量の可視化のノイズを減らすために、最適化のステップの前に摂動、回転やスケーリングを画像に適用することもあります。 他の正則化の選択肢には、周波数が高いところのペナルティ化 (近い画素の分散を減らす など)、 または、 学習されたプライアーから画像を生成する手法 (generative adversarial network(GAN) 66, denoising autoencoder 67 など) があります。

FIGURE 7.4: ランダムな画像による活性化関数を最大化する反復的な最適化。Olah, et al. 2017 (CC-BY 4.0) https://distill.pub/2017/feature-visualization/.
もし特徴量の可視化にもっと深く潜りたいなら、オンラインの論文誌 distill.pub、特に、私が画像を多く引用した Olah らによる特徴量可視化の投稿 68 や説明可能なブロックの構成に関するもの 69 を見てみてください。
7.1.1.2 敵対的サンプルとの繋がり
特徴量の可視化と敵対的サンプルには繋がりがあります。 両者の技術はニューラルネットワークのユニットの活性化を最大化します。 敵対的サンプルでは、敵対的な(間違った)クラスへのニューロンの最大活性化を探しました。 1つの違いは、スタート時の画像です: 敵対的サンプルでは、敵対的な画像を生成しようとした画像です。 特徴量の可視化では、アプローチによっては、ランダムノイズです。
7.1.1.3 テキストおよび表形式データ
ここでは、画像認識のための畳み込みニューラルネットワークの特徴量の可視化に焦点を当てます。技術的には、表形式データの為の全結合型ニューラルネットワークやテキストデータの為の再帰型ニューラルネットワークのニューロンを最大限活性化する入力を探すのにも何の支障もありません。 債務不履行予測では、入力は事前の信用の数値、携帯電話の契約数、住所やそのほか数十もの特徴量になるかもしれません。 ニューロンの学習された特徴量はその場合、数十の特徴量のいくつかの組み合わせになるでしょう。 再帰型ニューラルネットワークでは、ネットワークが学習したものは少しだけマシなものになるでしょう。 Karpathy et. al (2015)70 は再帰型ニューラルネットワークが実際にニューロンが説明可能な特徴量を学習することを示しました。 彼らは文字列において前の文字から次の文字を予測するという、文字レベルのモデルを訓練しました。 括弧開き "("" が現れると、ニューロンの1つが強く活性化され、対応する括弧閉じ ")"が現れたときに不活性化しました。 他のニューロンは行の終端で活性化しました。 URLで活性化するニューロンもありました。 CNNの特徴量の可視化との違いは、そのような例が最適化を通じてではなく、学習データへのニューロン活性化を調査することで見つかったことです。
いくつかの画像は、犬の鼻や建物といった周知の概念を表すように見えます。 しかし、どのように確信できるのでしょうか。 ネットワーク解剖の手法は人間の理解とニューラルネットワークの個別のユニットを結びつけます。 ネタバレ注意: ネットワーク解剖では、誰かが人間の理解によってラベル付けした追加のデータセットが必要となります。
7.1.2 ネットワークの解剖
Bau と Zhou ら(2017)71 による「ネットワークの解剖」の手法によって畳み込みニューラルネットワークのユニットの解釈性が定量化されました。 CNN チャンネルの大きく活性化している領域を人間の概念(物体、経路、模様、色...)で結びつけました。
特徴量の可視化 の章で見たように、畳み込みニューラルネットワークのチャンネルは新たな特徴量を学習します。 しかしこの可視化はあるユニットがある特定の概念を学習したということではありません。 あるユニットが例えば摩天楼をどれくらいよく検出しているかを測る方法もありません。 ネットワークの解剖の詳細に向かう前に、その研究の主題の前にある大きな仮説について話さなければなりません。 その仮説とは: (畳み込みチャンネルのような)ニューラルネットワークのあるユニットは解きほぐされた概念を学習する事です。
解きほぐされた特徴量の問題
(畳み込み)ニューラルネットワークは解きほぐされた特徴量を学習するのでしょうか? 解きほぐされた特徴量とはネットワークの個々のユニットが現実世界の特定の概念を 検出することを意味します。 畳み込みチャンネル394は摩天楼を検出し、チャンネル121はイヌの鼻を検出し、チャンネル12は30度の角度で縞をつける...などです。 解きほぐされたネットワークの反対は完全にもつれたネットワークです。 完全にもつれたネットワークでは、例えば、イヌの鼻を検出する個々のユニットはないでしょう。 すべてのチャンネルがイヌの鼻の認識に役立っています。
特徴量が解きほぐされていることはネットワークがよく説明できることを示しています。 知っている概念でラベル付けされた完全に解きほぐされたユニットをもつネットワークを感得てみましょう。 これによってネットワークの決定がなされる過程を追跡できる可能性を広がります。 例えば、ネットワークがどのようにオオカミとハスキーを分離しているかを解析できます。 はじめに、「ハスキーの」ユニットを特定します。 そしてそのユニットが前の層から「イヌの鼻」「ふわふわな毛皮」「雪」のユニットのうちどれに依存しているかを確認します。 そうすれば、そのネットワークが雪の背景のハスキーの画像をオオカミと間違って分類してしまうことがわかるでしょう。 解きほぐされたネットワークでは、問題がある何気なくない相関を特定できます。 それぞれの予測を説明するためによく活性化しているユニットとそれが何の概念についてかをすべて自動的にリストアップできます。 そのニューラルネットワークの傾向を簡単に探すことができます。 例えば、給料を予測するためにネットワークが「白い肌」の特徴量を学習するでしょうか。
ネタバレ注意: 畳み込みニューラルネットワークは完全に解きほぐされているわけではありません。説明可能なニューラルネットワークがどんなものであるか見るためにネットワークの解剖についてより詳しく見ていきましょう。
7.1.2.1 ネットワークの解剖のアルゴリズム
ネットワークの解剖は3つのステップからなっています。
- 縞から摩天楼まで人間がラベル付けした視覚的な概念を持つ画像を入手します
- それらの画像に対する CNN チャンネルの活性化度合いを計測します
- 活性化度合いとラベル付けされた概念の組み合わせを定量化します
次の画像はある画像がどうチャンネルに進んでいってラベル付けされた概念と一致するかを可視化したものです。
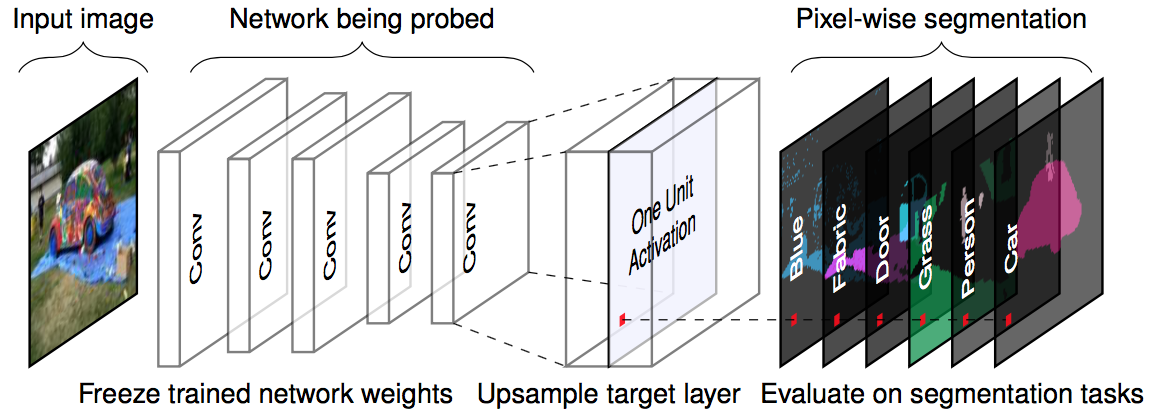
FIGURE 7.5: 与えられた画像と学習済みのネットワーク(重みが固定化されている)に対して、画像をターゲット層まで順伝搬して、活性化層の出力を元の画像サイズに合うようにスケールアップさせ、ground truth の pixel-wise セグメンテーションと活性化関数の最大値を比較しました。図は Bau と Zhou ら(2017)のものの引用です。
ステップ 1: Broden データセット
最初の困難だが重大なステップは、データ収集です。 ネットワーク解剖は、(色から街路の光景までのような)異なる抽象化レベルの概念によってピクセル単位でラベル付けされた画像を必要とします。 Bau & Zhou らは、いくつかのデータセットをピクセル単位の概念と結びつけました。 彼らはこの新たなデータセットを、広範(broadly)かつ稠密(densely)にラベル付けされたデータであることを表して ‘Broden’ と呼びました。 Broden データセットは殆どピクセルレベルまで断片化されており、一部のデータセットでは画像全体でラベル付けされています。 Broden は 60,000 枚の画像と、異なる抽象化レベルにおける 1,000 以上の視覚概念を含んでいます: 468の場面、585の物体、234の部品、32の物質、47の質感、11の色です。 次の画像では Broden データセットの幾つかのサンプル画像を示しています。

FIGURE 7.6: Broden データセットからの画像例。オリジナルは Bau & Zhou et. al (2017) によるもの。
ステップ 2: ネットワークの活性化を読み出す
次に、チャンネルごとおよび画像ごとに最も活性化している領域のマスクを作成します。 この時点では、概念ラベルはまだ関係ありません。
- それぞれの畳み込みチャンネル k について:
- Broden データセット内のそれぞれの画像 x について
- チャンネル k を含む目的の層への、画像 x の順伝播
- 畳み込みチャンネル k のピクセル活性化の抽出: \(A_k(x)\)
- 画像全体にわたるピクセル活性化 \(\alpha_k\) の分布計算
- 活性化 \(\alpha_k\) の0.005-分位点 \(T_k\) の決定。これは画像 x に対するチャンネル k の全活性化のうち 0.5% は \(T_k\) よりも大きいことを意味します。
- Broden データセット内のそれぞれの画像 x について:
- (場合によっては)低解像度の activation map \(A_k(x)\) を画像 x の解像度にまで拡大します。この結果を \(S_k(x)\) と呼びます。
- その activation map を二値化: 活性化閾値 \(T_k\) を超えるか否かにより、ピクセルがオンかオフになります。この新しいマスクを \(M_k(x)=S_k(x)\geq{}T_k(x)\) とします。
- Broden データセット内のそれぞれの画像 x について
ステップ 3: 活性化概念の団結 ステップ 2により、チャンネルおよび画像ごとに1つの活性化マスクを得ました。 これらの活性化マスクは強く活性化された領域を印付けます。 各チャンネルについて、チャンネルを活性化する人間的な概念を見つけたいです。 活性化マスクと全てのラベル付けされたコンセプトを比較することで、概念を発見します。 活性化マスク k と概念マスク c の間の団結を Intersection over Union (IoU) スコアにより定量化します。
\[IoU_{k,c}=\frac{\sum|M_k(x)\bigcap{}L_c(x)|}{\sum|M_k(x)\bigcup{}L_c(x)|}\]
ここで \(|\cdot|\) は集合の濃度です。 IoU は2つの領域の団結を比較します。 \(IoU_{k,c}\) は、ユニット k が概念 c を検出する精度として解釈できます。 \(IoU_{k,c}>0.04\) のときにユニット k を概念 c の検出器と呼ぶことにします。
次の図は1枚の画像に対する活性化マスクと概念マスクの IoU を説明しています。
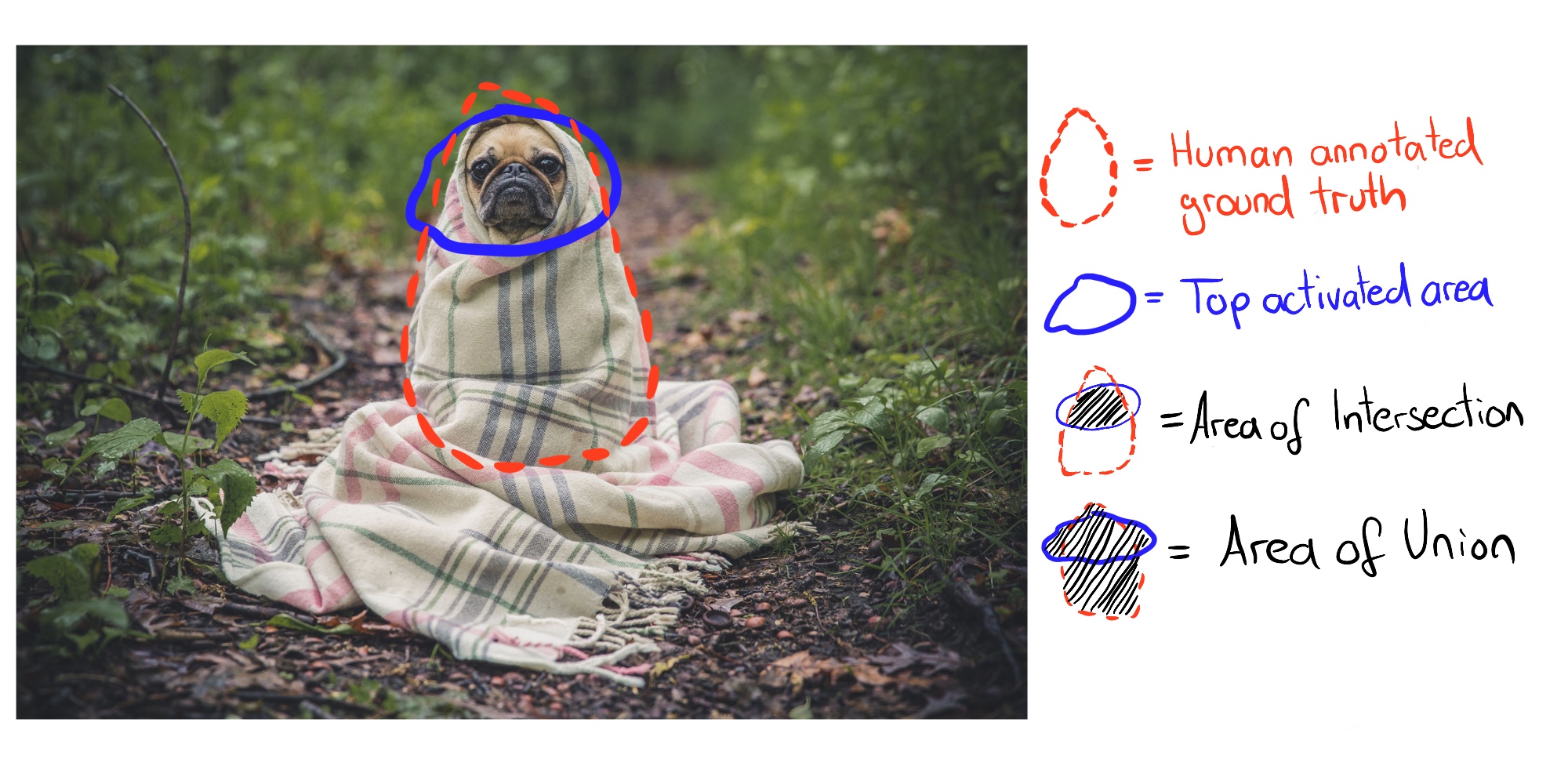
FIGURE 7.7: 人間がつけた正解アノテーションと最上位活性化ピクセルを比較して計算された Intersection over Union (IoU)。
次の図は犬を検出するユニットを見せています。

FIGURE 7.8: \(IoU=0.203\) で犬を検出する inception_4e のチャンネル 750 の活性化マスク。オリジナルは Bau & Zhou et. al (2017) によるもの。
7.1.2.2 実験
ネットワーク解析者達は様々なネットワーク構造 (AlexNet, VGG, GoogleNet, ResNet)を異なるデータセット(ImageNet, Places205, Places365)を用いて訓練しました。 ImageNet は物体に焦点をおいた1000のクラスの160万枚の画像を含んでいます。 Places205とPlaces365は205/365の異なるシーンからの画像240/160万枚の画像を含んでいいます。 彼らは追加で AlexNet をビデオフレームの順序や画像の色付けなどの自己管理型のタスクについて訓練しました。 これらの多くの異なる設定において、彼らは、解釈性の尺度として、unique concept detectors の数を数えました。 下記の物がいくつかの発見です。
- ネットワークは下の層で下位レベルの概念(色、テクスチャー)を検知し、上層で上位の概念を検知します(パーツ、物体)。 私たちは既にこれについて特徴量視覚化で学んでいます(#feature-visualization)。
- バッチ正規化により、unique concept detectors の数を減らします。
- 多くのユニットは同じ概念を検知します。 例えば、 \(IoU \geq 0.04\) を検知のカットオフとして使用した場合、ImageNet で訓練された VGG には 95(!)の犬のチャンネルがあります。
- 層の中のチャンネルの数を増やせば、解釈可能なユニットの数も増えます。
- ランダムな初期化の使用によって(異なるランダムシードと共に訓練すること)少しだけ異なる数の解釈可能なユニットに行き着くことがあります。
- Places356 で最も多くの unique concept detectors が学ばれ、次に Places205 と ImageNet が続きます。
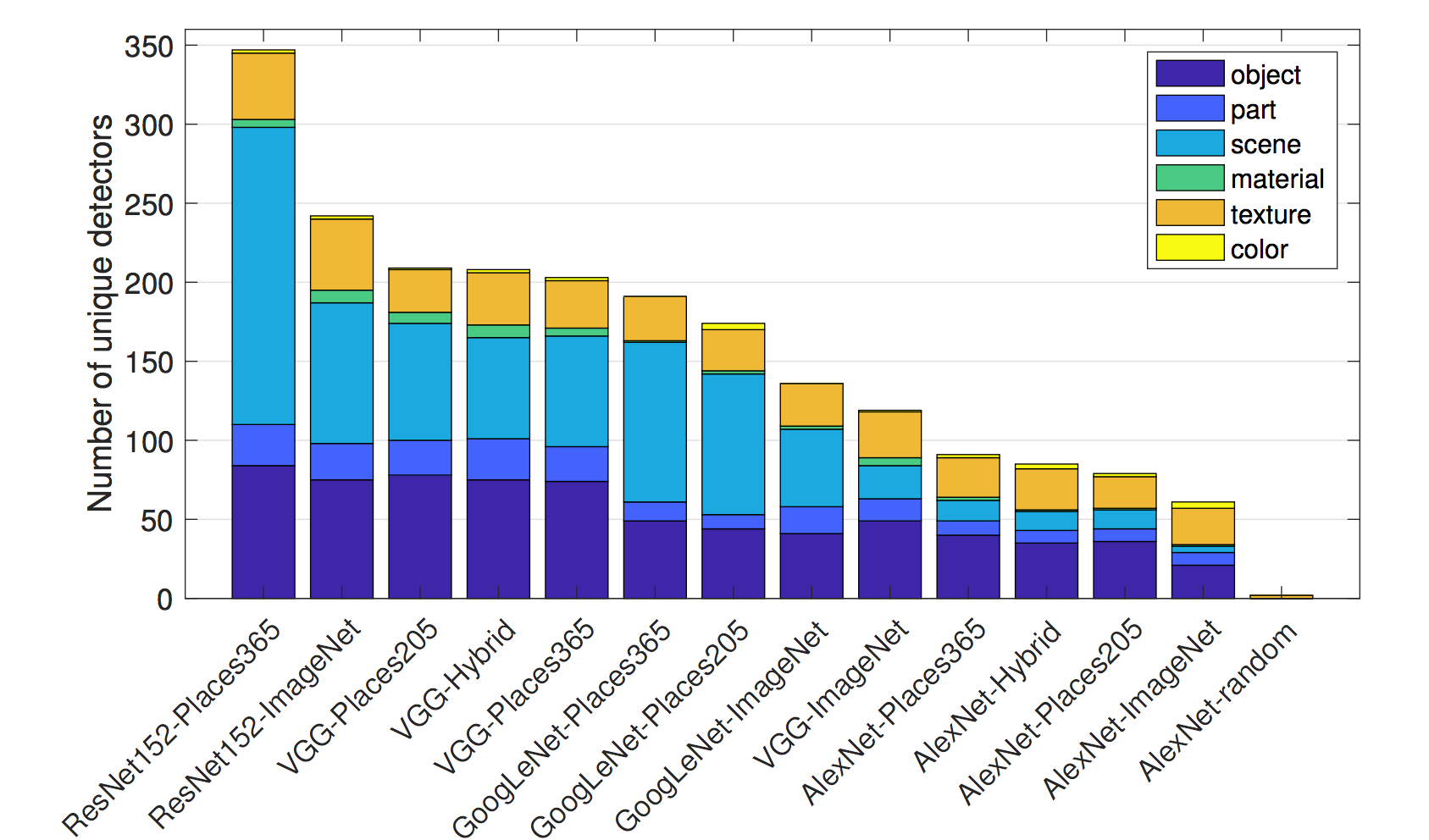
FIGURE 7.9: Places365で訓練されたResNetga一番多くのunique detectorsを持ちます。ランダムな重みを持つAlexNetが最も少ないunique detectorsの数を持ちベースラインの役割を果たします。. 画像は Bau & Zhou et. al (2017)からの出典です。
- 自己管理タスクで訓練されたネットワークは教師ありタスクで訓練されたネットワークと比べて少ない unique detectors を持ちます。
- 転移学習において、チャンネルの概念は変わります。例えば、犬の検知器は滝の検知器になりました。これは、最初、物体を分類するためのモデルを fine-tuning を使い、シーンを分類するためのモデルに変更しようとした時に起こりました。
- 実験のひとつで、著者は、チャンネルを新しいローテーション基底に投影しました。 これは ImageNet で訓練された VGG ネットワークで行われました。 "ローテーション"は画像が回転することを意味しているのではありません。 "ローテーション"は、私たちは画像の conv5層から 256 のチャンネルを取得し、元のチャンネルの線形結合として新たな 256 のチャンネルを計算することを意味します。 この過程で、チャンネルはかみ合います。 ローテーションは解釈性を減少させます。ex.概念に沿った、チャンネルの数が減少します。 ローテーションはモデルの性能を同じに保つために設計されました。 最初の結論は、「CNN の解釈性は軸に依存する」です。 これは、ランダムな組み合わせのチャンネルが unique concepts を検知する確率が低いことを意味します。 2つ目の結論は、「解釈性は識別力とは無関係」です。 チャンネルは直交変換で識別力を保ったまま変換できますが、解釈性は減少します。
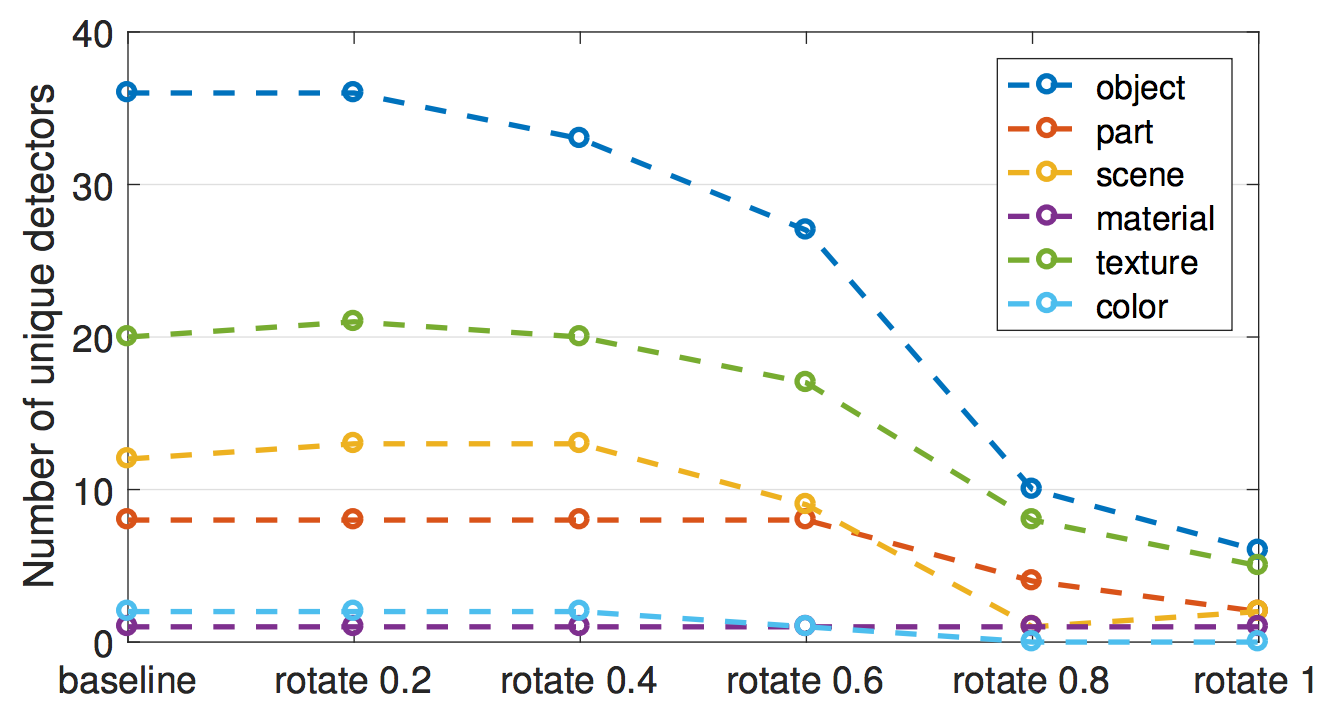
FIGURE 7.10: AlexNet,conv5(ImageNetで学習済み)の256のチャンネルがランダムな直交変換を使用して徐々に変更されると、unique concept detectorsの数は減少します 画像は Bau & Zhou et. al (2017).からの出典です。
著者は GAN (Generative Adversarial Networks) に対してもネットワーク解剖を行なっています。 GAN に対するネットワーク解剖は、こちらの[webサイト]((https://gandissect.csail.mit.edu/)をご覧ください。
7.1.3 利点
特徴量視覚化は、特に画像認識において、ニューラルネットワークの働きに対してユニークな視点を与えます。 ニューラルネットワークの複雑性と不透明性において、特徴量の視覚化はニューラルネットワークを分析、説明するための重要な一歩です。 特徴量視覚化を通して、ニューラルネットワークは最初にシンプルなエッジやテクスチャを検知し、次にもっと抽象的な部分、そして最後に物体検知の層になっていることがわかりました。 ネットワーク分析はこれらの洞察を拡大し、ネットワークユニットの解釈性を測定可能なものにします。 ネットワーク分析は、私たちに「概念を自動的にユニットとリンクさせること」を許します。これはとても便利です。 特徴量視覚化は、ニューラルネットワークがどのように動いているかを非技術的な方法で伝えるための素晴らしい手法です。 ネットワーク分析と共に、分類のタスクにおいてクラスを超えた概念**を検知できます。 しかし、私たちはピクセル単位でラベル付けされた概念を持つ画像のデータセットが必要です。
7.1.4 欠点
多くの特徴量可視化画像は全く解釈可能ではありませんが、それを表す言葉や精神的概念が存在しないような、いくつかの抽象的な特徴量を含んでいます。 学習データと同時に特徴量可視化を表示することは、助けになります。 画像はニューラルネットワークが何に反応し、"画像に何か黄色い部分があるはずだ"といったことだけを示すのかまでは、明らかにしないかもしれません。 ネットワーク解剖によっても、人間的な概念と結び付けられないチャンネルがあります。 例えば、ImageNet で訓練された VGG の conv5_3 層は(512のうち)193のチャンネルは人間的な概念と組み合わせられませんでした。
チャンネルのアクティブ化「のみ」を視覚化する場合でも、見るユニットが多くなりすぎます。 Inception V1 の場合、既に 5000 を超えるチャンネルが9つの畳み込み層からあります。 さらに負の活性化に加え、チャンネルを最大または最小に活性化する学習データからのいくつかの画像(例えば、4つの正、4つの負の画像)も表示する場合は、50000 を超える画像を表示する必要があります。 少なくとも、ネットワーク解剖のおかげで、ランダムな方向を調査する必要がないことは分かっています。
解釈可能の錯覚 特徴の視覚化は、ニューラルネットワークが何をしているのかを理解しているという錯覚を私たちに伝える可能性があります。 しかし、ニューラルネットワークで何が起こっているのかを本当に理解していますか。 仮に数百または数千の特徴の視覚化を見ても、ニューラルネットワークは理解できません。 チャンネルは複雑な方法で相互作用し、正と負の活性化は無関係であり、複数のニューロンが非常に類似した機能を学習する可能性もあり、特徴の多くについては人間に同等の概念は存在しません。 レイヤー7のニューロン349がヒナギクによって活性化されるのを確認できたからといって、ニューラルネットワークを完全に理解していると信じる罠に陥ってはなりません。 Network Dissection は、ResNet や Inception のような設計には、特定の概念に反応するユニットがあることを示しました。 しかし、IoU はそれほど優れたものではなく、多くの場合、多くのユニットが同じ概念に反応し、一部のユニットはまったく概念に反応しません。 チャンネルは完全に解きほぐされておらず、単独で解釈できません。
ネットワーク解剖の場合、ピクセルレベルでラベル付けされたデータセットの概念が必要になります。 これらのデータセットは、各ピクセルにラベルを付ける必要があるため、収集に多大な労力を要します。これは通常、画像上の物体の周囲に境界線を引くことでなされます。
ネットワーク解剖は、人間の概念を正の活性化と一致させるだけであり、チャンネルの負の活性化とは一致させません。 特徴の視覚化が示したように、負の活性化は概念とリンクしているようです。 これは、活性化の下位分位数をさらに調べることで修正される可能性があります。
7.1.5 ソフトウェアとその他の資料
Lucidと呼ばれる特徴視覚化のオープンソース実装があります。 Lucid Github ページにあるノートブックのリンクから、ウェブブラウザ上で簡単に試すことができます。 追加のソフトウェアは必要ありません。 他には Tensorflow の tf_cnnvis 、Keras のKeras Filters、Caffe のDeepVis で実装できます。 Network Dissection には素晴らしいプロジェクトのウェブサイトがあります。 ウェブサイトでは出版物の隣にコード、データ、活性化マスクなどが視覚化された追加資料がホストされています。
Nguyen, Anh, et al. "Synthesizing the preferred inputs for neurons in neural networks via deep generator networks." Advances in Neural Information Processing Systems. 2016.↩
Nguyen, Anh, et al. "Plug & play generative networks: Conditional iterative generation of images in latent space." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.↩
Olah, et al., "Feature Visualization", Distill, 2017.↩
Olah, et al., "The Building Blocks of Interpretability", Distill, 2018.↩
Karpathy, Andrej, Justin Johnson, and Li Fei-Fei. "Visualizing and understanding recurrent networks." arXiv preprint arXiv:1506.02078 (2015).↩
Bau, David, et al. "Network dissection: Quantifying interpretability of deep visual representations." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.↩